多くの方は、OS 標準の MS-IME か、Office に添付されている IME(便宜上 Office IME
と呼びます)を使っていると思います。
でも、大半の方は MS の IME は使い物にならないと言われていますね。僕も以前はそうでした。
MS の IME に我慢できない方の中には、サードパーティ製品の IME
を購入して使っている方も多くいらっしゃいます。特にメールや資料など日々日本語入力を頻繁にされる方はこの傾向が強くあります。
ライターは日本語入力を頻繁に使う代表選手のようなもので、快適な日本語入力を求めてサードパーティ製の IME
を使っている方が多くいらっしゃいます。
僕もライターをしているので、サードパーティ製の IME をずっと使っていました。
振り返ると、DOS 時代には A.I.soft の「WX」、Windows 時代に入って、WX の後継である「WXG」、A.I.soft が WX
シリーズの開発を終了して Just System の「ATOK」って経歴を持っています。
NDA 範囲になるのであまり詳しくは書けませんが、MS の IME チームと一緒に Office IME の改善テストにかかわっていました。当時僕は生粋の ATOK 使いだったし、MS-IME なんか使い物にならないと考えていた一人でしたが、テストをするために Office IME を使ってみると... 意外や意外、ATOK に勝るとも劣らない変換をするではないですか !!
色々フィードバックはしましたが、予想以上に使える IME に進化していたので、「Windows Server 2008
実践ガイド」はすべて Office IME で執筆しました。
発売された書籍で約700ページ、カットしたトピックスを全部含めると約1,000ページと
かなりのボリュームになった本ですが、日本語入力にストレスを感じることはほとんどなく、1冊を書きあげる事が出来ました。
ライターのヘビーな使用にも耐えられる Office IME のポテンシャルを引き出してみたくはありませんか?
嬉しい事に、Office (Office XP、Office 2003、Office 2007、Office 2010)
のライセンスを持っていれば、Office IME 2010 が無料で利用できるようになっています。Office IME 2010 を使いたい方は、以下の URL
からダウンロードしてください。
インストールは普通のアプリケーションのインストールと一緒なので難しい事はありません。
Office のサイト
http://www.microsoft.com/japan/office/2010/ime/default.mspx
ダウンロードセンター(Office サイトからダウンロードできない時はこちらからどうぞ)
http://www.microsoft.com/downloads/details.aspx?familyid=60984ECD-9575-411A-BD38-2294F17C4131&displaylang=ja
PC
のキーボードには漢字を直接入力するキーがありません。仮に漢字全てがキーボードに割り当てられていたら入力する事すら難しいものになってしまいますが...
その昔、ガリ版全盛期の頃には漢字を刻印した「活字」がびっしりと並べられて、そいつを1文字ずつ拾って打刻する「和文タイプライター」ってのがありましたが、お世辞にも使いやすいって代物では無かったのをよく覚えています。
コンピュータも元々日本語を扱うことが想定されておらず、全てアルファベットだけだったのが、次第にカタカナが導入され、漢字も使えるようにと進化してきました。
ところがここに困った事が1つ。
コンピュータに使用されているキーボードには日本語をフルに扱うだけのキーの数がありません。カタカナはキーマップできたのですが漢字が乗るにはあまりにもキーの数が少なすぎます。
この問題を最初に克服(?)したのが「句点コード入力」と呼ばれる、句点コードを入力して漢字にする方法でした。
この時代では、辞書のような句点コード表を引いて漢字一文字ずつコードを入力するという悪夢な様な日本語入力を真面目にしていたのです。(これしかなかったので)
次に登場したのが「単漢字変換」です。キーボードに刻印された「カタカナ」で読みを入力して漢字に変換するって入力方法です。当時のコンピュータエンジニアはアルファベットを使ってプログラムを書いていたので、アルファベットは流暢に入力できても日頃使わないカタカナのキー配列がわからず、日本語を入力する部分になるとキーボードの端から順番に文字を探しているって光景がよく見られました。
僕は、BBS
と呼ばれるパソコン通信の前世時代からコンピュータを触っていたので、キーボードに刻印されているカタカナをタッチタイプ出来ていたおかげて単漢字変換は苦にはなりませんでしたけどね(笑)
次に登場したのが「文節変換」です。確かローマ字入力もこの時代からだったように記憶しています。世に言うワープロ全盛期の幕開けで、コンピュータ(当時はワープロ専用機)が日本語入力機として使われ始めたのです。
多くの方がこの時代の使い方をそのまま踏襲されていると思います。
例えば「今日はよい天気です。」と入力したい場合は、多くの方が以下のように入力していると思います。
| きょうは[変換]よい[変換]てんきです。[変換] |
この文節変換は、従来の日本語入力から比べると飛躍的に入力効率が上がったので、ワープロが世に普及する原動力にもなったのでしょう。
最初は「かな」を直接入力する方法だったのですが、タイプライター文化を持たない日本人にとってキー配列を体で覚えてしまう「タッチタイプ」が難しかったのか、それとも日頃アルファベットを中心に使っていたコンピュータエンジニアが優先されたのかは不明ですが、配置を覚えるキーの数が少ないローマ字入力が出現して急速に普及し始めました。
今では目にする事がほとんど無い富士通の「親指シフトキーボード」もこの頃に生まれた物です。(親指シフトキーボードもタッチタイプ出来ていたのはナイショですw)
時代はさらに進み、単純な「日本語が入力できる」から「効率」求められるようになり、入力された日本語を解析して、より適切な漢字かなまじり文に変換する技術が各社で研究され今日に至っています。
適切な漢字かなまじり文に変換するには、入力された日本語を解析して「意味を推測」する必要があります。
例えば、「橋を渡る」「箸を使う」「端を歩く」はどれも同じ「はし」を使っていますが、「渡る」「使う」「歩く」と連動して「はし」が「橋」「箸」「端」に変わります。
このように日本語を文法的に解析して漢字を特定する技術が開発され、これがごく最近まで使われていました。(過去形にするのは言い過ぎですね。現在も使われています)
ここでお気づきでしょうが、文節変換だと変換効率を上げるための構文解析ができません。たとえば、
はしを[変換]わたる[変換]
では最初の文節での「はし」が橋・箸・端のどれなのか(これ以外も候補はありますが話を簡単にするために3つだけ)特定できないために、学習した変換順番に従った変換候補を出すしかありません。この変換学習を「辞書を鍛える」と巷では言ってました。
確かに、個人が良く使う言い回しには偏りがあるので、辞書を鍛えればある程度使い物にはなるのですが、使い始めは使えない候補ばかりが出てイライラさせられます。
従来の「単文節変換」では、構文解析の効果が出ないので「複文節変換」を試してほしいと A.I.soft の開発エンジニアから話を聞いて、僕の入力スタイルを単文節から複文節に変更したら、びっくりするくらい変換精度が上がったのをよく覚えています。(確定済み部分もバッファリングりしたとかの工夫はしていたようですが)
きょうはよいてんきです。[変換]
ごはんをたべるときにははしをつかう[変換]
こんな感じです。
単文節変換されている方は、一度複文節変換を試してください。変換精度がぐんと上がります。
この構文解析と、マッチングさせる辞書の開発が各社のノウハウとなり、IME 開発会社では日本語を研究する専門チームも編成されていました。
この構文解析で変換精度を上げた IME ですが、ある程度以上の精度には上がらない大きな壁にぶつかってしまいました。
その原因は「言葉の多様性」です。同じ日本語でも「話し言葉」と「書き言葉」は結構違いますし、上下関係にも大きく左右されます。更には方言やスラングなんかもあり、そもそも文法で解析すること自体に無理があったのです。
だって、我々は厳密に日本語の文法や単語の意味を意識して日本語を使っているわけではありませんよね。新しい言葉も次々に出現して日本語そのものが少しずつ変化しています。
言葉とは元来曖昧な物で、「こういう具合に表現すると、多くの人に意図が伝わるらしい」って程度のものです。
もし厳格な文法や単語の意味に従っていたら、時代劇とか、もっと前に使われていた日本語を我々は使っているはずですが、そんな事ありませんし。(それはそれで楽しいかもですがw)
英語/日本語間などの言語間機械翻訳も同様な問題を抱えており、文法解析の限界を超えるために生まれたのが「コーパス」です。
コーパス(コーパス言語学と言うのが正しいかも)とは、文例を使った翻訳の仕組みで、膨大な文例の中から最も似た表現を選出して、その対訳を翻訳としてした使うのが基本的な仕組みです。
構文解析が文法から意味を理解するのに対して、コーパスは似た文例を探してくるだけなので意味を理解するってプロセスがありません。つまり、コンピュータはただ探してくるだけで意味を全く理解していないって事になります。
コーパスの良い所は、文例を新しいサンプルに変えれば言葉の変化に追従できる点です。
コーパスの考え方は古くからあったのですが、この仕組みを実現できるコンピュータが今まで無かったので、コーパスは理論と研究室でのテスト実装しか存在していませんでした。ところが、コンピュータの処理能力が加速度的に向上し、コーパス稼働させることが出来るコンピュータが簡単に手に入るようになり近年やっと動くものが登場したのです。
MS Office 2007 に入っている Office IME 2007 から、このコーパスが搭載されました。
「ウソだぁ。Office IME 2007ってかなりのおバカじゃん」と反論もあるでしょう。Office IME 2007 にはコーパスが搭載されましたが、実は(ry
この問題は SP2 で解消され、本来のポテンシャルに更なる磨きをかけた精度が引き出せるようになっていますので、必ず SP2 を適用して下さい。SP2 は Microsoft Update と直接ダウンロードで提供されています。SP2 情報は、以下の URL を参照してください。
http://www.microsoft.com/japan/office/2007/sp2/default.mspx
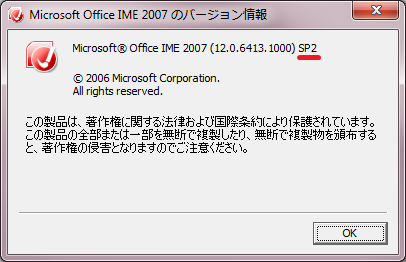
お使いの Office IME のサービスパックがよくわからない場合は、Office IME のツール(道具箱アイコン)をクリックして[ヘルプ]-[バージョン情報]で確認できます。
「SP2」以降ならOK
Office IME 2010 は最初から対策済みなのでこのアップデートは不要です。
Office IME はコーパスを使っているので、ユーザ学習がゼロの状態でも良い感じの変換をしてくれます。これは、ユーザ学習辞書への依存度が大幅に下がっており、使い始めたその日から使い物になるって事を意味しています。
構文解析をするにせよ、コーパスを使うにせよ、単文節変換では効果がないことは既に説明しました。IME
を賢く使うには長めの入力をしてから変換する必要があります。
ところがライターをやっていると、この「変換」のオペレーションすら思考の妨げになるんですよね。
望ましい姿は「書き手はひたすらひらがなを入力するだけ」です。変換と確定は IME
が勝手にやってくれるのが一番です。それも間違いなく適切な日本語にって条件付きでw
この「IME が勝手に変換と確定をする」って機能の事を「自動変換」と言います。WXG や ATOK
には自動変換機能があり、適切な日本語に変換された所から自動確定してくれます。
残念ながら、Office IME
にはこの自動変換機能はあるのですが、コーパスをより有効に機能させようとして未変換文字列の長さを長めに設定していると、変換動作が重くて使い物になりません(Office IME 2010
は大幅に改善されていますが、それでももたつく感が残っています)。でも、設定次第で快適に自動変換させる事が出来ます。
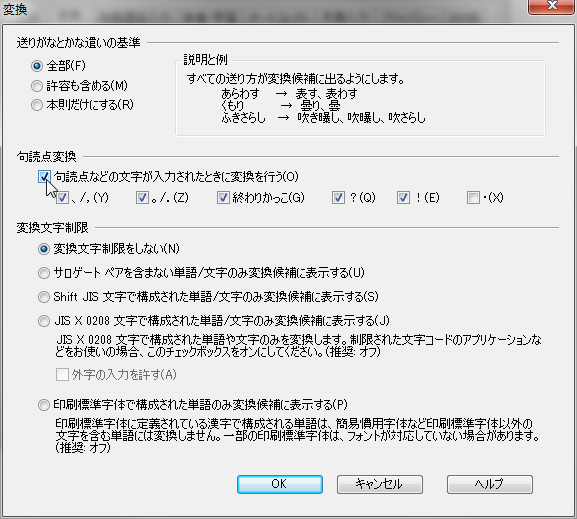
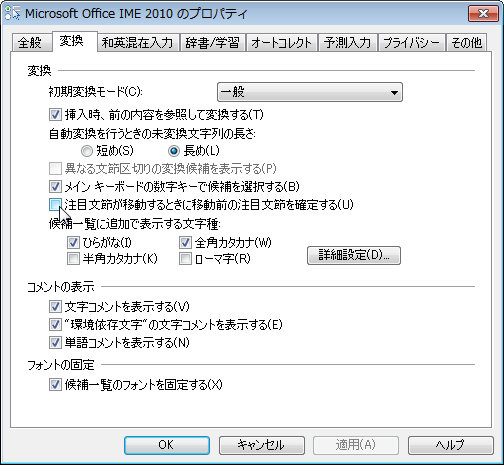
自動変換を快適にするには、句読点を変換トリガーに指定します。
Office IME 2007 で変換動作がもたつくようであれば「注目文節が移動するときに移動前の注目文節を確定する」をチェックしてで積極的にバッファを開放する
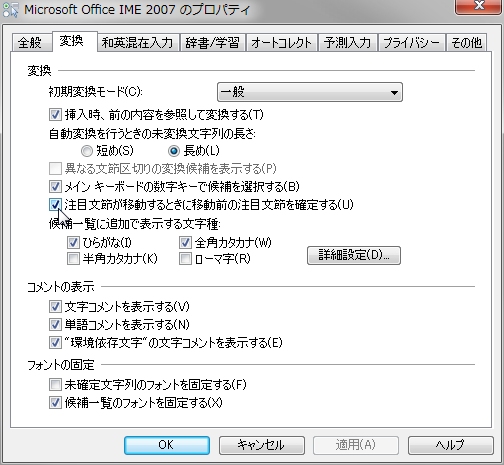
変換トリガーは詳細設定の中にある
句読点変換を有効にして、トリガーとなる句読点を指定
この状態で日本語入力をしてみましょう。変換キーを押したくなるのをぐっとこらえて、ひたすらひらがなを入力すると、ほら自動変換しているでしょ。それも結構な精度で変換しているのに驚くはずです。
Office IME
2010 は、動作が大幅に軽くなったので、「注目文節が移動するときに移動前の注目文節を確定する」でバッファを積極的に開放しなくても十分使い物になります。
ただし、句点(。)だけを変換トリガーにしていると少しもたつくので、読点(、)も変換トリガーに入れるのがおすすめです。
Office IME 2010 では「注目文節が移動するときに移動前の注目文節を確定する」をチェックしなくても OK
ATOK もそうなのですが、変換精度はまだ完璧な領域には達していないので、読み直しをしている時に所々変換修正が必要ですが、これは Tips にある「再変換」で補うことが出来ます。
Office IME 2007 では、新しい辞書が提供されても Windows Update
等で自動更新されることはなく、利用者がダウンロードしてセットアップする必要がありましたが、Office IME 2010
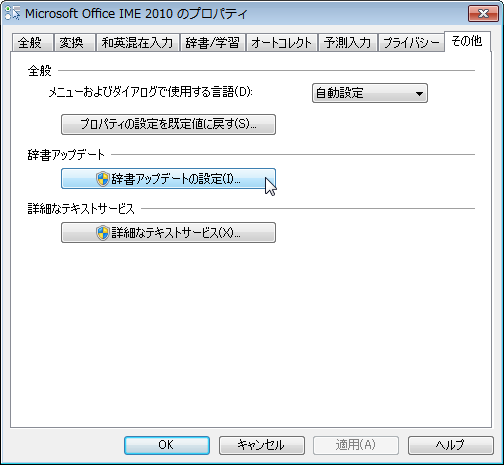
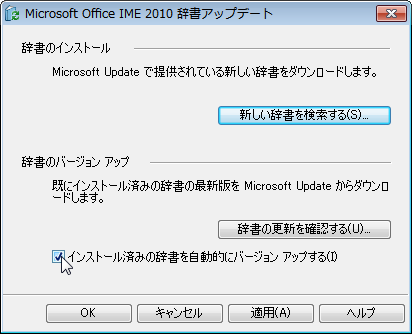
から辞書の自動更新がサポートされました。
辞書の自動更新は、デフォルト OFF なので、ON に変更しておきましょう。
辞書アップデート設定
辞書の自動更新を有効にする
自動変換は、どんどん日本語を入力する良い方法ですが、誤変換が悩ましいんですよね。誤変換の修正はどうしていますか?
誤変換した文字を消して、また日本語入力していませんか?
実はそんな事しなくても良いんです。間違っている文字を選択して「再変換」すれば... あら不思議、もう一度変換できちゃいます。
誤変換されている文字を選択
再変換キー([変換]キー)を押す
デフォルトだと、[スペース]の右隣のキーのハズ
表示された変換候補から適切なものを選択
ちょっとした英単語を書かなくちゃいけないけど、スペルが怪しい時ってがありますよね。そんな時はカタカナから英単語に変換しちゃいましょう。
カタカナ英語辞書を一般使用に入れる
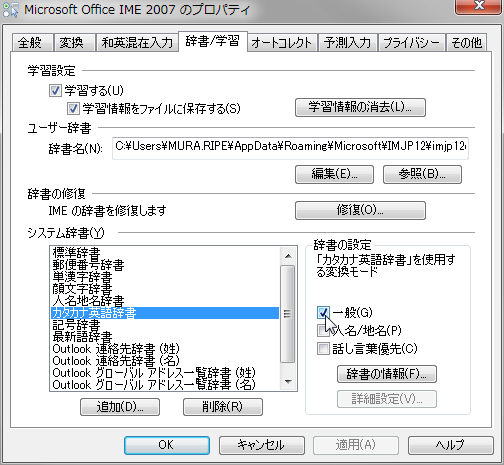
カタカナで入力
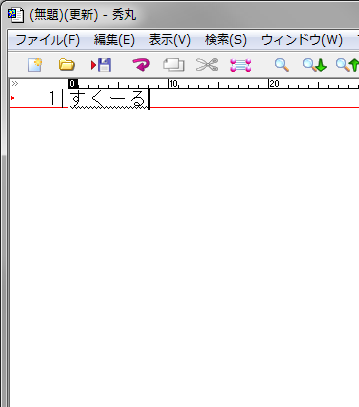
英単語が候補に出る
より使いやすいIMEにするため、誤変換をフィードバックしましょう。フィードバック結果は順次リリースされている辞書に反映されているようなので、今まで変換出来ていなかった単語も変換できるようになるかもです。
フィードバック送信時には、送信しようとしている内容が表示され、送りたくない内容は削除できますので安心してフィードバックできます。
フィードバックを有効にする
あまり更新頻度は高くありませんが、IME チームも blog を書いています。技術的な内容や辞書のリリースもアナウンスされています。ひょっとすると、裏話なんかもあるかも....
コーパスは、現在 MS が提供している文例しかありません。一個人が書く文章には偏りがあるので、個人が書いた文章をクロール(収集)すればより使っている人になじむ
IME になるはずですね。
更に、企業などの組織にも特有な書き方があるので、組織レベルのの文章をクロールすれば、もっと幸せになれそうな気がします。
コーパスの優先順位はこんな感じかな
組織 > 個人 > システム
タイプミスって、人によって傾向が強いように感じます。Office IME には「オートコレクト」と呼ばれる自動訂正機能がありますが、これをもっと進化させて、入力者のタイプミス傾向を学習してくれると良いと思いませんか?
僕は「かな入力」人種なので、促音(っ)や拗音(ゃゅょ)入力の Shift
キーが残って、意図しない文字入力になる事が良くありますし、濁音/半濁音のタイプミスもしょっちゅうやらかしちゃいます。
あるいは隣のキーをたたいたり、タイプが浅くて文字抜けしたりと.... (タイピング練習し直せってツッコミはナシで ^^;)
これらの傾向を自動学習して、自動補正してくれると嬉しいんですけどね。
標準辞書で用法を間違いやすい単語の意味は表示されるのですが、これをもっと拡張して「反意語」とか「同義語」とか「ことわざ」とか「四文字熟語」とかの辞書がサポートされると個人的には嬉しかったりします。特に反意語と同義語のシソーラス系の辞書は、物書きしていると、言い回しを考えるときにどうしても欲しくなる機能なんですよ。(シソーラス辞書ツールを別に買っていたり)
サードパーティ製品はオプション辞書が充実していますが、残念ながら Office IME ってこのあたりが弱いんですよね。
業界辞書なんかもニーズとしては結構ありそうですね。
![]()
![]()
Copyright © MURA All rights reserved.